NAME
pattern expressionsSYNTAX
pe help
pe [qualifier] [Setname:] pattern_expression [constraints]*
pat [qualifier] [Setname:] pattern_expression [constraints]*
with
pattern_expression: token_ref* [position_ref] token_ref*
position_ref : '<' [0-9]+ '>'
constraint : '@' [0-9]+ ' ' '(' token_expression ')'
and
qualifier: 'and' or '&'
DESCRIPTION
Pattern expressions specify sequences of token references, optionally followed by constraint specifications. They are similar to regular token expressions, but they allow for some simplifications. Like token expressions, pattern-expressions support name binding.The pattern expression can optionally be followed by a name followed by a colon to define that the patterns matched by the expression are to be stored in a named set, where they can then be manipulated with the dp (display pattern) command. Named pattern sets themselves can be managed with the ps (pattern set) command. Matched patterns that are stored in named sets can also be accessed (added to, deleted from, or scanned) from within Cobra inline programs.
The meta-symbols supported in regular expressions (re) are: ( | ) . * + ? The ^ symbol to negate a match (i.e., ^name matches all tokens different from name). And, finally, the square brackets are used to list a choice of tokens for matching. Pattern expressions are simpler, because the symbols ( | ) + and ? are now treated as normal characters, unless they are preceded by a backslash. (Starting with Cobra version 3.3 from January 18, 2021.)
The characters * and ] are treated as meta-symbols unless they are immediately preceded by a space. Similarly, the [ character is a meta-symbol (for starting a range of possible single tokens to match) unless immediately followed by a space.
Name binding is the same as for token expressions. A name is bound to a token position by prefixing it to the token matching pattern (e.g., @ident) followed by a colon (e.g., x:@ident). The bound name can be referenced by repeating the name preceded by a colon later in the expression (e.g., :x).
Normally a token-name must be matched exactly, but by preceding the name with a leading / character the match can be defined as another (embedded) regular expression. Note: the pattern expression itself is a regular expression over tokens as units, and in this case a regular expression can also occur within the pattern to match token-names. To escape the special meaning of / in this context, precede it with a backslash character.
By giving multiple pe and/or re commands consecutively, the set of matches can be modified if the qualifier & is used. As usual, the qualifier must follow the command name, and precede the Setname, if present.
The best way to display the results of a pe command is to use either the dp or the json or json+ commands.
Qualifiers As qualifiers, only & is supported. If other types are used (i.e., ir, top, or up), they are silently ignored. Using the qualifier no triggers a warning and prevents the search from completing.
Constraints and Position References (new)
General constraints are supported in Cobra version 3.4 from 5 March 2021, and later,
and position references are supported in Cobra versions from 14 May 2021 and later.
A constraint can be used to attach an additional Boolean condition to a token that must
evaluate to true for the token tobe considered a match. Constraints can refer to any of
the standard token attributes.

A constraint is preceded by a '@' symbol that is followed by a number. If no position
references are used, the number is interpreted to refer to the state in the generated
NDFA where the constraint must be applied.
If, however, aat least one position reference is used in the pattern, then the number that
follows the '@' symbol is interpreted to refer to the position in the pattern that was labeled
with the same number. In this case it isn't necessary to inspect the NDFA for the correct place
of the match. (This method was inspired by the Coccinelle pattern syntax.) A position reference,
finally, is a number enclosed in angle braces, as in: <1>.
Any one constraint can be applied at multiple positions in a formula (meaning that the a position reference with the same number can appear in multiple places in a pattern), but any position reference can only refer to a single specific constraint.
As an example, we can attach a condition to an open curly brace that limits matches to curly braces that enclose at least 75 lines of source text, by using the following single token expression with the added constraint:
: pe { @1 (.range >= 75)
The constraint is specified at the end of the token expression, as an @-symbol that is
followed by a number. The number refers to the state in the NDFA that Cobra
generates from the token expression itself. In this case, it is a single state automaton,
so the constraint is simply attached to it's only state, which is numbered 1.
The best way to figure out what the correct state number is to attach a constraint to is to
generate the NDFA in graphical form and display it, by using the -view commandline
option, as in:
$ cobra -view -pe '@ident ( .* ) { .* } @6 (.range > 75)' file.c
wrote '/tmp/cobra_dot_2kdRgx'
By default, the NDFA is displayed with dot and looks as shown on the right
(click for a larger version). Here we use the expression to find functions that are
longer than 75 lines of text, which means that we want to put the constraint on the
open curly brace of the function body. In the NDFA we can see that this corresponds
to state number 6, which means that we must tag the constraint with @6.
The above pattern expression can be written more conveniently with a position reference, as follows:
$ cobra -pe '@ident ( .* ) { <1> .* } @1 (.range > 75)' file.c
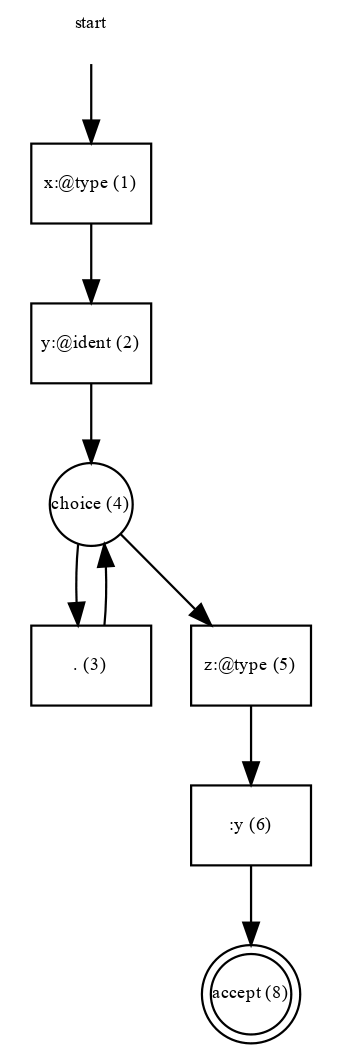
Another example of a constraint, this time using bound variable matching, with output
generated in json+ format, is:
$ cobra -json+ -pe 'x:@type y:@ident .* z:@type :y @6 (:x != :z)' *.[ch] $ cobra -json+ -pe 'x:@type y:@ident .* z:@type :y <1> @1 (:x != :z)' *.[ch]By generating the NDFA you can see that the state to bind the constraint to is number 6 (and not 5), because we want both variables x and z to have obtained their bound values before the constraint is applied. For x this happens at state 1, and for z it happens at state 5.
{kind=link}
The position reference in the second version of the pattern makes this process much simpler of course, makeing it unnecessary to refer to the underlying NDFA.
EXAMPLES
: pe goto x:@ident \; :x : # match gotos immediately followed by the target label
: pe { .* malloc ^free* } # blocks that contain calls to malloc but not free
: pe switch ( .* ) { ^default* } # switch statements without a default
: pe { .* @type x:@ident ^:x* } # unused variable declarations in a block
: pe else if ( .* ) { .* } ^else # if-then-else-if chain not ending with else
: pe ^void @ident ( .* ) { ^return* } # non-void functions without a return statement
: pe ^void @ident ( .* ) { .* return \; .* } # non-void functions failing to return a value
: pe for ( .* ; .* [< <=] .* ; .* ^[++ +=] ) # strange for statements
: pe /restore ( .* ) { .* } # match functions with a name containing "restore"
: pe \/restore ( .* ) { .* } # match functions with a name containing "/restore"
: terse on # terse output
: dp # display all matches
: terse off # normal mode
: track start file # divert output to file
: json "this is bad" # json format output to file
: track stop # output back to stdout
: pe @ident @1 (.len == 1 && !.curly && !.round) # find single-letter global identifiers
: pe @ident @1 (.len > 32 && .curly >= 1) # local identifiers greater than 32 chars
Note that there must be at least one space before and after every token reference, except when
followed by the Kleene star *, or when preceded by the negation symbol ^.
An example of using named sets:
$ cobra *.c # cobra sources
: pe A: for ( x:@ident .* ) { .* :x = .* }
9 patterns stored in set 'A'
: dp A 1 # display first pattern matched
...
: pe B: for ( .* ) { .* emalloc .* }
7 patterns stored in set 'B'
: dp B 7 # display last pattern matched
...
: ps C = A & B # set intersection
: ps D = A + B # set union
: ps E = A - B # set difference
: ps F = B - A
: ps convert F # convert the patterns in set C to markings
: json patterns from set F
: q
$
To display the results in a named set with the json
output command, remember to first convert the pattern set into token markings
(for unnamed sets this happens by default), as we did in the example.
:It is easy to express most of the Power of Ten rules as token expressions, at least in spirit. Here's a list:
: pe x:@ident ( .* ) { .* :x ( .* ) .* } # use of recursion, p10 rule 1a
: pe [goto setjmp longjmp] # use of goto setjmp or longjmp, p10 rule 1b
: pe for ( .* \; ^[< <= > >=]* \; .* ) # loop condition must contain comparison, p10 rule 2a
: pe for ( .* \; .* < .* \; ^[/+]* ) # loop bound, missing increment, p10 rule 2b
: pe for ( .* \; .* > .* \; ^[/-]* ) # loop bound, missing decrement, p10 rule 2c
: pe ^/init ( .* ) { .* [/alloc /free] .* } # using malloc outside init, p10 rule3
: pe @ident ( .* ) { <1> .* } @1 (.range > 75) # functions longer than 75 lines, p10 rule4
: pe @ident ^> @1 (!.curly && !.round && .len==1) # single letter globals, p10 rule6a
: pe ^void x:@ident ( .* ) { .* } ^[/= /> /<] :x ( .* ) ^[/= /> /<] # not checking return value, p10 rule7a
: pe @ident ( .* * :x@ident .* ) { ^:x* ^[/= /> /<] :x ( .* ) ^[/= /> /<] .* } # not checking validity ptr param, p10 rule7b
: pe [\#ifdef \#ifndef] ^EOF* [\#ifdef \#ifndef] # XXX no more ifdefs than .h files, p10 rule8a
: pe \#define @1 (.fnm != /\.h$) # use defines only in .h files, p10 rule8b
: pe typedef ^/_ptr ^\;* * ^\;* \; # typedef hides a ptr deref, p10 rule9a
: pe * * * @ident # more than 2 levels of deref, p10 rule 9b
: pe @ident -> @ident -> @ident -> # more than 2 levels of deref, p10 rule 9b
: pe * * @ident -> # more than 2 levels of deref, p10 rule 9b
: pe * @ident -> @ident -> # more than 2 levels of deref, p10 rule 9b
One other rule says that variables should be declared at a low level of scope, which is hard to
express as a pattern expression, but luckily there is already a standalone cobra check for just this
property (bin_linux/scope_check).
Another rule requires that the assertion density of code is minimally 2% on average. This is easier to check with standard queries and a script, and still be formulated tersely. For instance, as follows:
: m assert; >1; r; m \;; >2; # assertion ratio, p10 rule5
: %{ if (50*marks(1) < marks(2))
{ print "counted " marks(1) " assertions; should be > " marks(2)/50 - 1 "\n";
}
Stop;
%}
Here we used two sets, one with assertions and one with semi-colons (terminating statements).
By comparing the sizes of the two sets we can then come close to figuring if the assertion
ratio is in the right ballpark.
NOTES
Be careful with patterns that are not bounded somehow to a portion of the input stream. A bad idea, for instance, would be to use a pattern:: pe .* # bad ideawhich would match the entire input from first to last token. Similarly, in a pattern like this:
: pe x:@ident -> .* if ( :x /= NULL ) # not boundedto find cases of reverse null checks, the ".*" in the middle can match anything, so it is not necessarily restricted to function boundaries. A better version then is:
: pe { .* x:@ident -> .* if ( :x /= NULL ) .* }
even though it now includes two additional wildcard matches, it assures that a match
does not go outside a brace pair.
Also remember that a pattern expression is applied to tokens, so the pattern "." (a dot) by itself matches any token, not token-names of one character. Therefore, if we wanted to match token-names of exactly three characters, we have to do this with a little detour, for instance as follows:
: pe . <1> @1 (.len==3)where the initial dot matches any token, and the constraint then limits matches to token-names of the right length.
In a pattern expression the symbol + (plus) can have special meaning so it has to be handled with care. It is best, also in pattern expressions, to write [++] rather than a plain ++, if the increment operator is meant, to make sure the second + sign is not interpreted as a meta-symbol.
When the pe command completes it will report what the bound variables were for each match of the
complete pattern, if there are bound variables.
Cobra also marks the tokens in each matched pattern with a nonzero value of the .mark field.
- 1 All tokens that are part of a matched pattern are marked by adding a 1 value to the .mark field (with a binary or operation: .mark |= 1). Three additional marks are also added.
- 2 The first token in the pattern is marked with value 2 (resulting in a total mark value of the token of: 1+2=3).
- 4 Lexical tokens corresponding to matched bound variables are marked with additional value 4 (resulting in 1+4=5) (for places where a bound variable is defined see 16 below).
- 8 The last token in the pattern is marked with value 8 (resulting in: 1+8=9).
- 16 Lexical tokens corresponding to the location where a bound variable is defined (1+16=17) (for matches see 4 above).
- Lastly, the first token of the pattern is also bound to its last token, with an assignment to the .bound field. This can be useful in scripts where this field can more easily be checked and used.
: m & (.mark & 2)or alternatively, to just isolate the bound variables from each pattern matched with:
: m & (.mark & 4)Finaly, the json display option summarizes the patterns matched more concisely than the regular display options do, by giving the range of line-numbers matched, with an optional message to describe the type of match:
: json "pattern expression matches"In this format, though, no source text is shown, nor are the bound variables identified. To add that information, use the new json+ command:
: json+ "pattern expression matches"
Matching of brace pairs: More detail on how braces are matched in pattern expressions can be found in the following overview, which also explains command-line use of pattern searches: pattern searches.