
FeaVer: Search Process
The search process used by FeaVer to identify property violations as quickly as possible is motivated by the following observations:
- First the bad news. The number of theoretically possible executions of any non-trivial system, say a telephone switch, is unimaginably large. Consider, for instance, how many subscribers could simultaneously attempt to place a call, how many distinct combinations of feature packages could be enabled on any one subscriber line, or how many different sequences there could be for generating onhook, offhook, flash, and dial events from a phone.
- The good news is that for any software bug there are usually both extremely complicated and fairly simple examples that can demonstrate its existence. In practice one typically encounters the complicated cases first. Much time can be lost if only these cases are available to a (human) debugger to diagnose and repair a problem. Once a bug is understood it is usually easy to write down the simplest possible manifestation of that problem in a bug report. With automated verification techniques we can systematically search for the simple examples directly and report those to the system engineers first. The good news is that for a mechanical verifier the simpler scenarios can be found the fastest: the opposite from the typical experience in manual testing.
Iterative search refinement
In the initial verification runs that are meant to return results quickly the FeaVer system selects scenarios randomly from the large set of scenarios that is theoretically possible. The scope of the random pruning is slowly broadened in each subsequent run: the system starts with a series of fast and approximate searches, and in a series of incremental steps it then slowly broadens the scope of the searches and starts spending more time on cases that have not reveal any errors in the earlier runs. This continues until exhaustive coverage is reached, or until an error is found, whichever comes first. The figure on the left shows an interactive display of the search in progress, for every property being checked a horizontal line appears on this display. Lines are grouped by feature, and within a feature group each separate line can be clicked to interrogate it about the specifics of the property. The line grow from left to right as the search progresses through the iterative phases; it turns red and stops growing as soon as an error is discovered and has been reported. By clicking the line, the failure scenario can then be inspected.

FeaVer's iterative search process intercepts bugs from the most obvious ones down to the most subtle and obsure ones, in phases. The glaring bugs are reported in seconds, more subtle ones in minutes, and the most obscure (and often least interesting) types of bugs can be hunted down overnight or in the idle moments of unused system time.
Violations are reported to the user via a web-based interface, as standard source level C execution sequences, or graphically in the form of sequence charts. The same web-based interface is used to access the database of properties, and optionally to initiate checks. (More detail.)
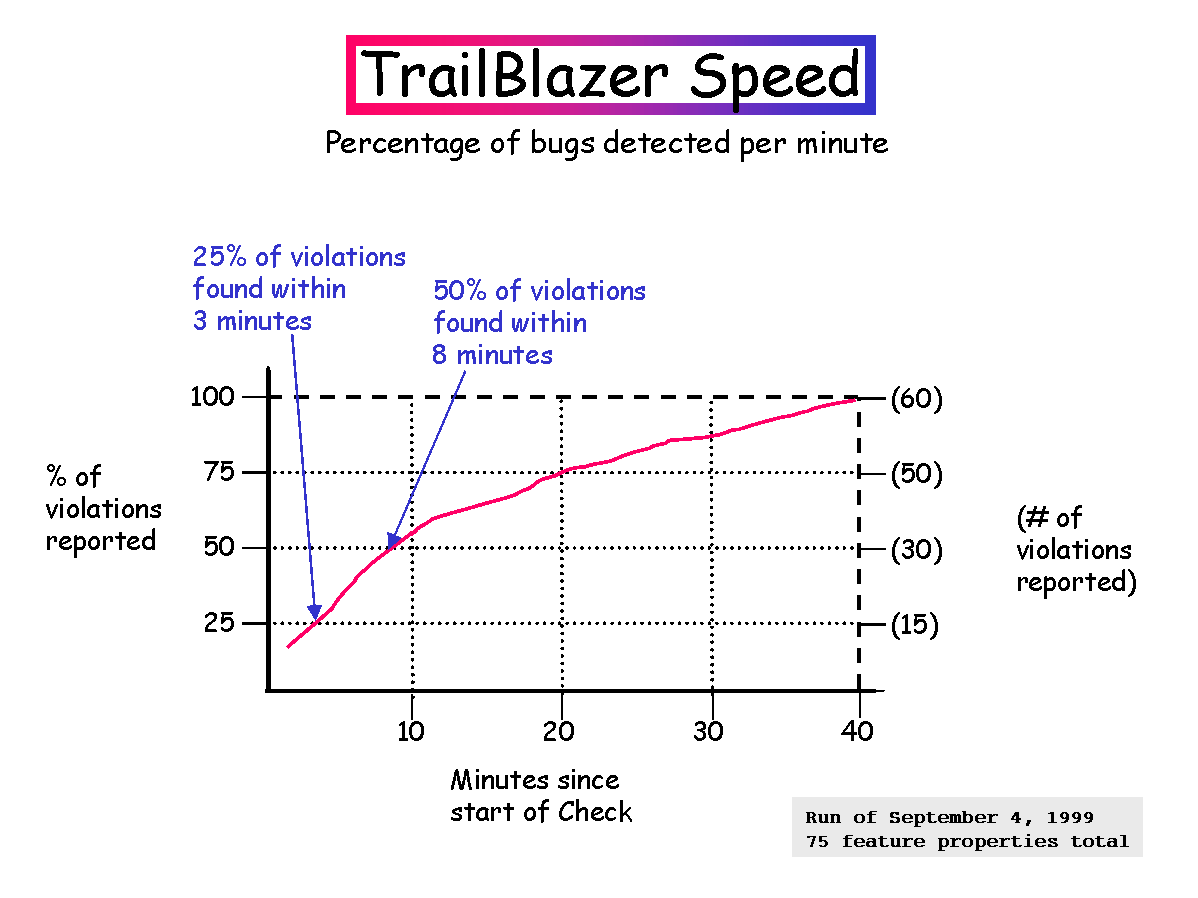
TrailBlazer
FeaVer can also initiate searches autonomously when it detects that a requirement for the system was added or modified, when one or more of the test-drivers was changed, or when the source itself was changed. When the source changes, the user will usually have to make small updates of the lookup table that is used in the model extraction process. FeaVer will in that case prompt the user for the required changes: the precise entries to be added to the lookup table, and the ones that can be deleted from it. The user can chose to ignore this update process and allow the search to proceed without user interaction. FeaVer will in that case assume that any added code in the system can be interpreted as a don't care in the verification process. When properties or test driver definitions change, usually no other changes are needed, and the search for errors can be initiated immediately.In automatic mode, the system will start with an interative broadening process to find errors in the shortest amount of time. This process is cut-off after about 5 iterations, when an adequate level of coverage has been achieved. FeaVer will then start a second phase in the search, where it looks at each property violation that was found in the first phase, and will attempt to find a shorter equivalent of that violation. It will again do so wby iterative searching: it sets an artificial upperbound on the length of an execution that it is willing to consider and will step by step increase that bound until an error is found, or the length of the existing sequence is exceeded.
The first phase of the AutoMode therefore attempts to cast its nets very broadly, iteratively refining the coverage up to a preset maximum; the second phase hunts down and tries to improve the error reports on the specific error cases that were discovered. When the system is otherwise idle (most of the time, until properties change or the software application itself changes) it can spend arbitrary amounts of time to refine the results stored in the database in this manner.